perception • robotics • engineer

|
Raaj here. I've been building computer vision systems for over a decade, for a variety of research, commercial and industrial platforms, with multiple publications and patents in the field. Most recently, i've been building vision systems for humanoid robots at Agility Robotics. Prior to this, I was doing research at the CMU Robotics Institute working under the esteemed professors Srinivasa Narasimhan and Yaser Sheikh and earned a masters along the way. Before that, I did a stint building vision systems for large scale industrial robots for the Singapore Changi Airport with SpeedCargo. And prior to that, I was building vision systems for underwater robots with Bumblebee. My resume is linked right here |





|
|

|
Carnegie Mellon University Masters, Masters of Science in Robotics (MSR) CMU Robotics Institute 2018 ─ 2021 |

|
National University of Singapore Bachelors, Computer Engineering Minor in Technopreneurship 2012 ─ 2016 |
|
|

|
|
|
|

|
|
|
|

|
webpage |
abstract |
pdf |
talk |
code
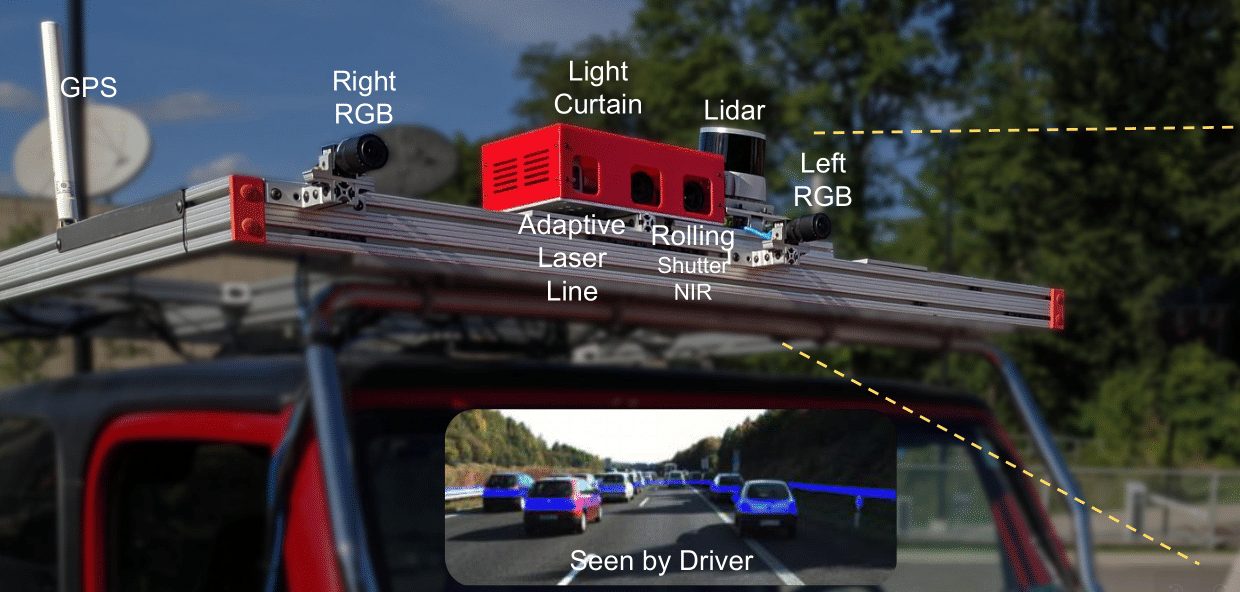
Active sensing through the use of Adaptive Depth Sensors is a nascent field, with potential in areas such as Advanced driver-assistance systems (ADAS). They do however require dynamically driving a laser / light-source to a specific location to capture information, with one such class of sensor being the Triangulation Light Curtains (LC). In this work, we introduce a novel approach that exploits prior depth distributions from RGB cameras to drive a Light Curtain's laser line to regions of uncertainty to get new measurements. These measurements are utilized such that depth uncertainty is reduced and errors get corrected recursively. We show real-world experiments that validate our approach in outdoor and driving settings, and demonstrate qualitative and quantitative improvements in depth RMSE when RGB cameras are used in tandem with a Light Curtain. |

|
webpage |
abstract |
pdf |
talk |
code
Most real-world 3D sensors such as LiDARs perform fixed scans of the entire environment, while being decoupled from the recognition system that processes the sensor data. In this work, we propose a method for 3D object recognition using light curtains, a resource-efficient controllable sensor that measures depth at user-specified locations in the environment. Crucially, we propose using prediction uncertainty of a deep learning based 3D point cloud detector to guide active perception. Given a neural network's uncertainty, we derive an optimization objective to place light curtains using the principle of maximizing information gain. Then, we develop a novel and efficient optimization algorithm to maximize this objective by encoding the physical constraints of the device into a constraint graph and optimizing with dynamic programming. We show how a 3D detector can be trained to detect objects in a scene by sequentially placing uncertainty-guided light curtains to successively improve detection accuracy. |

|
|

|
webpage |
abstract |
pdf |
code
We present the first single-network approach for 2D whole-body pose estimation, which entails simultaneous localization of body, face, hands, and feet keypoints. Due to the bottom-up formulation, our method maintains constant real-time performance regardless of the number of people in the image. The network is trained in a single stage using multi-task learning, through an improved architecture which can handle scale differences between body/foot and face/hand keypoints. Our approach considerably improves upon OpenPose, the only work so far capable of whole-body pose estimation, both in terms of speed and global accuracy. Unlike OpenPose, our method does not need to run an additional network for each hand and face candidate, making it substantially faster for multi-person scenarios. This work directly results in a reduction of computational complexity for applications that require 2D whole-body information (e.g., VR/AR, re-targeting). In addition, it yields higher accuracy, especially for occluded, blurry, and low resolution faces and hands. |

|
webpage |
abstract |
pdf |
talk |
code
We present an online approach to efficiently and simultaneously detect and track 2D poses of multiple people in a video sequence. We build upon Part Affinity Fields (PAF) representation designed for static images, and propose an architecture that can encode and predict Spatio-Temporal Affinity Fields (STAF) across a video sequence. In particular, we propose a novel temporal topology cross-linked across limbs which can consistently handle body motions of a wide range of magnitudes. Additionally, we make the overall approach recurrent in nature, where the network ingests STAF heatmaps from previous frames and estimates those for the current frame. Our approach uses only online inference and tracking, and is currently the fastest and the most accurate bottom-up approach that is runtime-invariant to the number of people in the scene and accuracy-invariant to input frame rate of camera. Running at $\sim$30 fps on a single GPU at single scale, it achieves highly competitive results on the PoseTrack benchmarks. |

|
|

|
|

|
abstract |
pdf |
talk
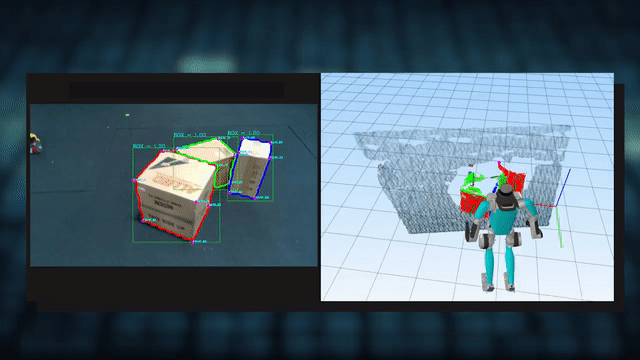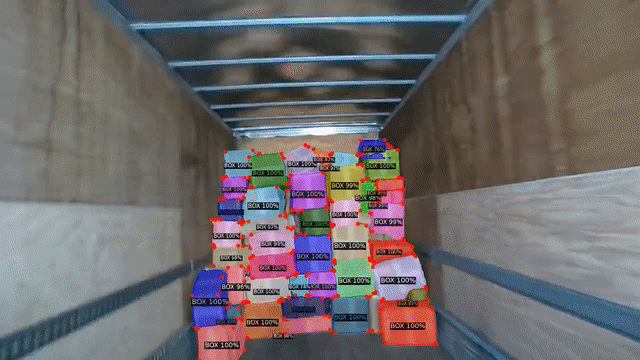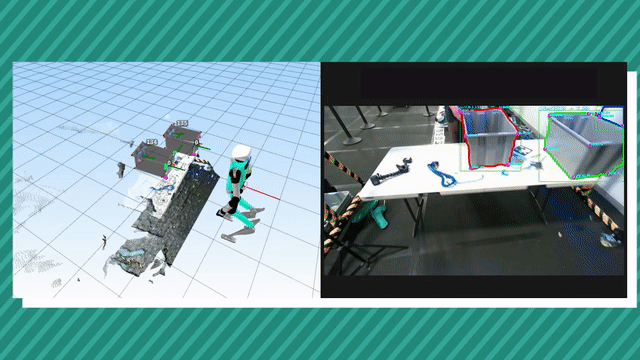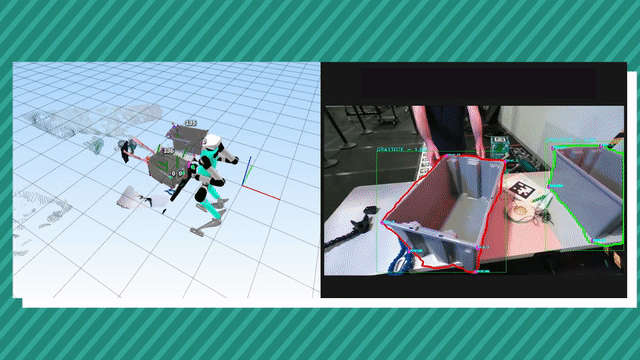
This paper presents a novel algorithm for extracting the pose and dimensions of cargo boxes in a large measurement space of a robotic gantry, with sub-centimetre accuracy using multiple low cost RGB-D Kinect sensors. This information is used by a bin-packing and path-planning software to build up a pallet. The robotic gantry workspaces can be up to 10 m in all dimensions, and the cameras cannot be placed top-down since the components of the gantry actuate within this space. This presents a challenge as occlusion and sensor noise is more likely. This paper presents the system integration components on how point cloud information is extracted from multiple cameras and fused in real-time, how primitives and contours are extracted and corrected using RGB image features, and how cargo parameters from the cluttered cloud are extracted and optimized using graph based segmentation and particle filter based techniques. This is done with sub-centimetre accuracy irrespective of occlusion or noise from cameras at such camera placements and range to cargo. |

|
abstract |
pdf |
talk
Visual tracking of an object in 3D using its geometrical model is an unsolved classical problem in computer vision. The use of point cloud (RGBD) data for likelihood estimation in the state estimation loop provides improved matching as compared to 2D features. However, point cloud processing is computationally expensive given its big data nature, making the use of mature tracking techniques such as Particle Filters challenging. For practical applications, the filter requires implementation on hardware acceleration platforms such as GPUs or FPGAs. In this paper, we introduce a novel approach for object tracking using an adaptive Particle Filter operating on a point cloud based likelihood model. The novelty of the work comes from a geometric constraint detection and solving system which helps reduce the search subspace of the Particle Filter. At every time step, it detects geometric shape constraints and associates it with the object being tracked. Using this information, it defines a new lower-dimensional search subspace for the state that lies in the nullspace of these constraints. It also generates a new set of parameters for the dynamic model of the filter, its particle count and the weights for multimodal fusion in the likelihood modal. As a consequence, it improves the convergence robustness of the filter while reducing its computational complexity in the form of a reduced particle set. |

|
|
|
abstract |
pdf |
talk |
patent
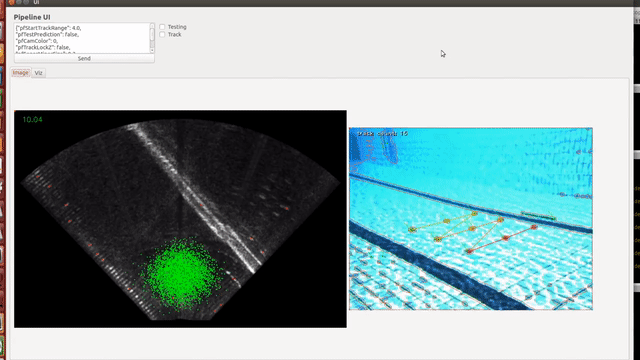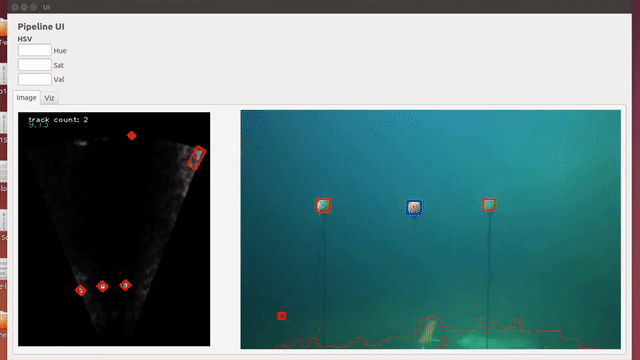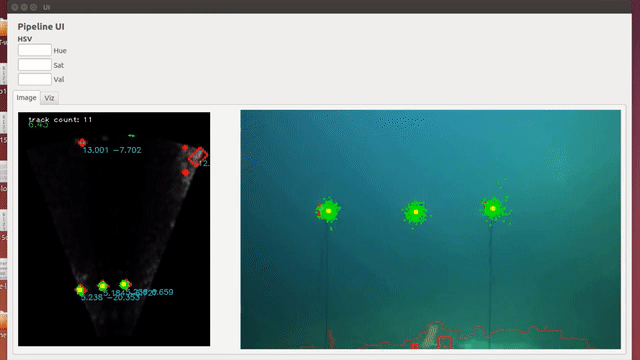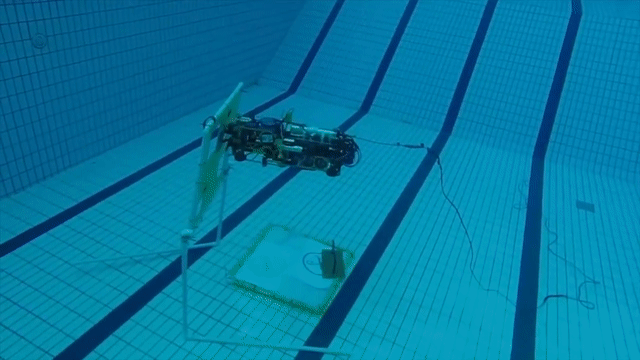
Underwater Object Localization is widely used in the industry in Autonomous Underwater Vehicles (AUV), both in sea and lake environments for various applications. Sonars and Cameras are popular choices for this, but each sensor alone poses several problems. Data extraction from Optical Cameras underwater is a challenge due to poor lighting conditions, hazing over large distances and spatio-temporal irradiate (flickering), while Sonars tend to have coarser sensor resolution and a lower signal-to-noise ratio (SNR) making it difficult to extract data. This makes false positives more likely. In this paper, we present a robust method to localize objects in front of an AUV in 3D space, using camera imagery, sonar imagery and odometry information from onboard sensors. This is done through various image processing techniques, and a hybrid sonar/camera particle filter based calibration step and fusion step. |

|
|
|
Being a vision person, i quite enjoy photography as a side hobby. And living in the Pacific Northwest, I enjoy imbibing in the great outdoors, with a little hiking, rock climbing, and some mountaineering. I enjoy keeping up to date with all the new technology in our ever evolving field, and most recently built a maze solver conditioned on images with a diffusion based approach. Checkout my github for more projects. |
|
Template modified from this |